
Traditionally, scraping required foundational coding knowledge, but ChatGPT has made scraping data a lot easier.
There are three ways you can scrape a website using ChatGPT.
Firstly, you can use the Scraper plugin to help you collect data. No coding knowledge is necessary. You just need access to ChatGPT Plus and know how to instruct the plugin, which I will walk you through here.
Secondly, you could also use ChatGPT to write code for your browser’s console. This requires some HTML and CSS knowledge, but is a much more efficient way to collect data as compared to manual copying.
Lastly, you could also ask ChatGPT to write code for a scraping library. I am most familiar with Puppeteer because I am primarily a JavaScript programmer. But other mainstays include BeautifulSoup, Scrapy or Selenium for Python users.
Essentially, you’d want to ask ChatGPT to write in a language that you’re most familiar with since you might end up needing to modify the code.
Table of Contents
- Method 1: Scraper – the easiest way to scrape data with ChatGPT plugin
- Method 2: Using Google Chrome Inspector’s Console to Scrape Website with ChatGPT
- Method 3: Use ChatGPT to write code for a scraping library (Puppeteer, BeautifulSoup, etc.)
- ChatGPT Scraping Makes Life Easier
- More AI tutorials
Method 1: Scraper – the easiest way to scrape data with ChatGPT plugin
Scraper left me wondering if I should have just abandoned writing this post because it’s making my other techniques obsolete.
The other two methods does require some manual labour. You might end up needing to copy, paste, or run a program.
Compared to the other two methods, Scraper can potentially serve as a one-step solution to your scraping task.
With Scraper, you just tell it what to do. If you prompted it correctly and the website is formatted simply, you will get cleanly formatted data that you can copy-paste into Google Sheets.

Let’s say I want to find out the countries’ capitals, but I only want the countries that start with A. I want it in a table format with Country and Capital as the two column headers.
My prompt:
Scrape https://www.scrapethissite.com/pages/simple/
Create two columns, populate the first column with country name and the other column for capital.
Only enter countries that start with AHere’s the output:

For web pages that only have a single page, doesn’t require AJAX, pagination or anything fancy, this method works great.
However, when I tried the exercise with pagination, it wasn’t able to navigate between pages. I prompted with this,
Scrape http://www.scrapethissite.com/pages/forms/
Find all Team Name in Year 2011 with Win % more than 0.500.
Output these team names and their Win % in descending order in a two-column table
The front page only had data from 1990 and 1991. Whereas data for 2011 involved going to the last pages.
So, I got this error message:
The data scraped from the website is a long text string. Unfortunately, it doesn't contain the information for the year 2011. The data provided is only for the years 1990 and 1991.
To get the information for the year 2011, we would need to interact with the website's interface, which is beyond the capabilities of the current web scraping tool.
If you have a different website or webpage that contains the information in a static format (i.e., doesn't require interaction with the webpage), I'd be happy to help scrape that for you.This demonstrates that Scraper does have its limits.
Filtering out unwanted data with Scraper

Sometimes you’ll want to copy specific parts of a web page but filter out some sections. Scraper can help you do that.
We want the names of the 27 exercises from this website, but we don’t want the “Click me to see the sample solution” link.
So I prompted,
Scrape: https://www.w3resource.com/python-exercises/web-scraping/index.php
Find all the paragraphs that start with a number. Copy the text that follows and put it in a table.And I got this output,

Scraper truncated the output at number 10, but telling it to “continue generating” got it to output the rest.
Method 2: Using Google Chrome Inspector’s Console to Scrape Website with ChatGPT
Scraper might make short work of websites that are easy to scrape, but you might need the following technique some time in the future.
This technique uses the console in a web browser to distill information so that it’s easier to copy.
Let’s say I want to copy all the H2 headings on this Wikipedia page on web scraping.

You’ll need HTML and CSS knowledge because you will have to know to write a query.
Open up your Chrome Inspector. In Windows, you can press F12 or CTRL+SHIFT+I
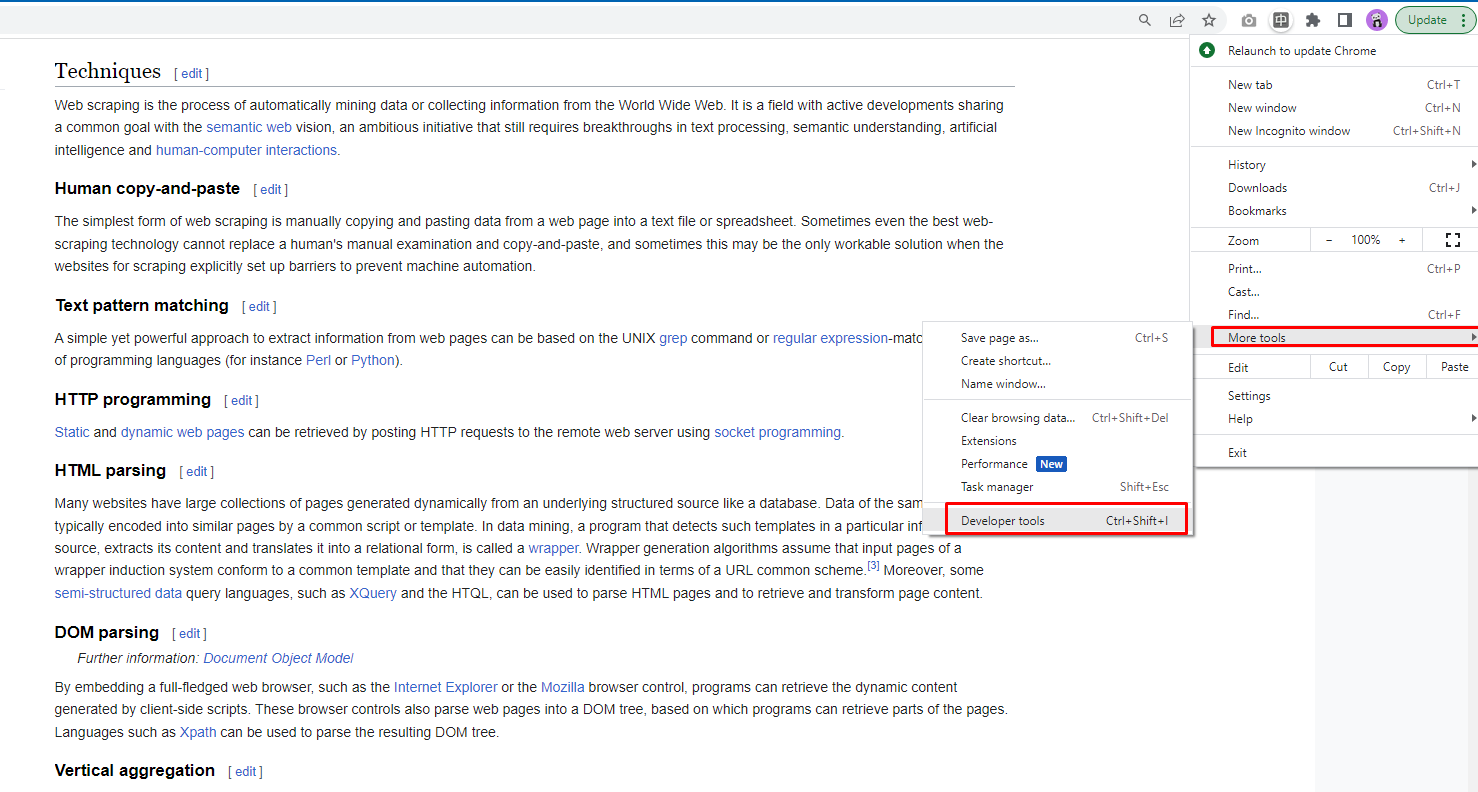
Look through the Elements tab and find out how these subheadings are formatted.

It seems that all of these subheadings are actually a <h3> with two <span>s nested within the H3.

The first span is a headline, with class mw-headline. The second span is the edit button, which we don’t want.
Therefore, to get the text in the first span, we want to target all <h3>s with a class of mw-headline .
To test whether this is the right selector, I ran the following in the console.
document.querySelectorAll("h3 > .mw-headline")Then, I got this:

The results numbered 0 to 7 is what we want, but that’s OK, it’s easy to manually delete them later.
Using ChatGPT to write code to scrape in Inspector
Our goal is to have the content formatted so we can paste it into a spreadsheet. Each subheading should go into a new row.
Therefore, we can use this prompt
Write code for the Google Chrome Inspector console
Store the innerText of all "h3 > .mw-headline", creating a newline after each.
console.log once doneThe first line tells ChatGPT where you will use the code
The second line tells ChatGPT to capture all the data and create a new line (/n ; equivalent to pressing return/enter).
The third line pushes out the content. Like this:

Since each subheading is a new line, you can easily copy and paste it into Google Sheets and you will see this.

As you can see, I omitted the subheadings that I didn’t need.
You must log everything in one go for easy copying
You might be wondering why can’t we use a simpler prompt that logs out each entry as it gets processed. Because you will get this:

Then, when copied to Google Sheets, you will get this,

A use case when scraping with Google Chrome Inspector
What we’ve scraped shows a simple example with eight entries.
This technique really shines when you have a huge amount of data. For example, if you are copying a massive amount of quotes.
If you are on ChatGPT 3.5, this remains a very valuable technique. Or if Scraper can’t do what you need it to do — for example, navigate.
Another example using Chrome Inspector and scraping with ChatGPT

Let’s say I want to scrape 10 pages of this website, Quotes To Scrape.
Remember that Scraper, the ChatGPT plugin, can’t navigate, which is why I have chosen to use the Google Chrome console scraping method.
I want to get the quote, and then place the author after the quote. So, for the first quote in the screenshot, it should be:
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.” by Albert Einstein
How to set up the Chrome Inspector code with ChatGPT
The format is [quote’s text] + [“by”] + [author’s name].
First, you need to think of the steps on how to get this formatted.

Notice that the quote’s text and author’s name is contained within a <div> with class .quote.

Write code for Google Chrome Inspector.
The structure of the code is this: ".quote" has two children ".text" and ".author"
Write code that will query all .quotes and store the innerText of ".text" + "by" + ".author" in a variable, ending each entry with a newline.
Once you have reached the last entry, console.log the variableDescribe this to ChatGPT to create the scraper, and this comes out,
let quotes = document.querySelectorAll('.quote');
let quoteTexts = '';
quotes.forEach((quote, index) => {
let text = quote.querySelector('.text');
let author = quote.querySelector('.author');
if (text && author) {
quoteTexts += `${text.innerText} by ${author.innerText}`;
if (index !== quotes.length - 1) {
quoteTexts += '\n';
}
}
});
console.log(quoteTexts);After running it, I get this output,

Looks like a mess, but if you copy it into Google Sheets, it’s properly formatted. The “newline” requirement in the prompt makes it that each quote goes into a new row.

With the same code, run it across the 10 pages that you want to scrape, and in no time, you will get a huge spreadsheet.

The benefit of this method lies in its ability to save you a lot of time if you are scraping a lot of data.
Instead of manually copying each quote, you can now just copy-and-paste the console output. You just went from minutes per page to mere seconds.
Method 3: Use ChatGPT to write code for a scraping library (Puppeteer, BeautifulSoup, etc.)
Let’s do the same exercise as above, except this time, we will use Puppeteer, a JavaScript library that I use for scraping.
This script will do the following:
- Opens a new browser and a new page in that browser.
- Navigates to the target webpage.
- In a loop for 10 iterations, it:
- Scrapes the page for the quote text and author text.
- Stores these in an array.
- Navigates to the next page if it exists.
- Parses the collected quotes to CSV format and writes it to a file named ‘quotes.csv’.
- Closes the browser.
You could use anything you’re familiar with, such as BeautifulSoup. In my case, I will use Puppeteer.
We’d have to modify the prompt a little.
Write code for Puppeteer.
Go to http://quotes.toscrape.com/
Then, scrape the content on the page, using the following instructions.
The structure of the web page is this: ".quote" has two children ".text" and ".author"
Write code that will query all .quotes and store the innerText of ".text" + "by" + ".author".
Once you have reached the last entry, click the <li> with class "next".
When the next page has loaded, repeat the scraping instructions until 10 pages have been scraped. Then output the stored innerText into a CSVThere are three bolded sentences which contain changes to the Google Chrome Inspector scraping code. To start, make sure to change “Google Chrome Inspector” to the scraping library you’re using.
In the first bolded sentence, I tell the scraper where to go. Puppeteer has an page.goto() function and I am simply just writing the instructions in plain language.
Secondly, we want the scraper to click onto the next page button, which is a <li> with class .next.
The last bolded sentence tells the scraper to do 10 pages and then output its gleanings into a CSV.
The rest of the code hasn’t been changed from the last example.
Does the scraping code from ChatGPT work?
I always feel a tense moment when I take the code from ChatGPT to Visual Studio Code where I will run it.

Shockingly, it did work.
In 26 seconds, I was able to get 100 quotes scraped.

ChatGPT Scraping Makes Life Easier
I remember the old days when I had to write Puppeteer or console code myself. I enjoyed it, though it did take much more time than writing logical instructions to ChatGPT.
Right now, my first go-to scraping tool would be Scraper, the ChatGPT plugin. Scraper requires little analysis of the code as Scraper will do it for you. All you do is write plain language.
However, Scraper can hit the wall very quickly, which is why you’d have to bring out the traditional methods which involve analyzing the HTML to find patterns that will help you in your scraping.
I believe AI can really help you in many ways, and here are my most useful free tools.
More AI tutorials






Have a project in mind?
Websites. Graphics. SEO-oriented content.
I can get your next project off the ground.
See how I have helped my clients.
